结论先行:refactor 适合你对要重构的代码范围已经很清楚,或者对局部代码进行快速重构的情况。refactor-plan 适合你对系统了解还不多,无法评估重构带来的影响范围有多大的情况。
前言
重构既是一个技术术语,也是一项任务边界可大可小的工作。
当我们对大模型说『请帮我重构一下代码』时,背后的需求可能是:
- 某个特定的类、函数或方法、变量的局部重构。
- 某个功能模块下的多个类、配置文件的职责再分工。
- 整个系统架构的代码组织已经臃肿到难以为继,亟需重构。
第一种情况只是把一个 80 行的函数拆成 3 个小函数,第二种情况可能是一次涉及 20 个文件的模块边界重组。第三种情况则可能涉及到对架构层的调整,波及整个应用的绝大部分代码。
范围不同,重构策略完全不同,用错方法可能会给程序员带来意想不到的风险。
再次强调:
重构和重写不是一回事。
Martin Fowler《重构》一书说得很清楚:重构是渐进的、行为保持不变的改进;重写则是推倒重来的。
大多数由重构引起的悲剧是:用重写的思路做重构。一开始觉得我们只是修改几小段代码,但事情可能不会如你预估的那么顺利。随着关联的改动越来越多,问题非但没有解决,反而衍生出许多新问题。最糟糕的还是:没有配备足够的测试用例。
如今,随着 AI Coding 的普及,越来越多的代码由大模型生成。当 80-90% 的代码由大模型生成后,如果想重构代码却没有科学合理的思路,其结果将是灾难性的。
今天的文章中,我将分享两个不同的重构技能,帮助你在需要对代码进行重构时,知道该选择哪个。
对比的两个 Skill
refactor
npx skills add https://github.com/github/awesome-copilot --skill refactor在这个 Skill 的说明文档中,有一段话非常明确地说明了这个技能的适用范围:
Improve code structure and readability without changing external behavior. Refactoring is gradual evolution, not revolution. Use this skill for improving existing code, not rewriting from scratch.
这个技能适用于对已有代码的渐进式重构(gradual evolution)。如果希望进行大规模重构甚至推倒重来,那么这个技能并不适合。
进一步阅读 SKILL.md 文档,可以看到在「When to use」部分,作者明确指出了这个技能的触发时机:
Use this skill when:
- Code is hard to understand or maintain
- Functions/classes are too large
- Code smells need addressing
- Adding features is difficult due to code structure
- User asks “clean up this code”, “refactor this”, “improve this”
这些条件说明了运用该技能的最佳时机是:使用者很清楚某个类或函数的代码已经到了亟需重构的地步。
当我们使用 AI Coding 对代码进行持续迭代,而缺乏良好的规范指引时,很容易就会形成大段的、冗余的甚至是废弃的代码。这个时候使用 refactor 技能对特定代码文件进行检查,并找出存在坏味道的地方,就是一个明智的选择。
重构前的原则
refactor 这个技能对于重构的实施提出了明确的要求:
The Golden Rules
- Behavior is preserved - Refactoring doesn’t change what the code does, only how
- Small steps - Make tiny changes, test after each
- Version control is your friend - Commit before and after each safe state
- Tests are essential - Without tests, you’re not refactoring, you’re editing
- One thing at a time - Don’t mix refactoring with feature changes
这里每一条原则都来自无数程序员的惨痛教训。从这些原则中我们可以窥见「科学重构」的思想:
在明确不改变代码功能的前提下,将重构分解为多个小步骤,每个步骤的重构都要通过版本控制做好随时回滚的准备,同时每次重构前、重构后都需要用测试驱动开发的理念进行验证。
10 种 Bad Smell 及其背后的重构思想
refactor 这个技能之所以能够如此受欢迎,原因在于其 SKILL.md 中列举了 10 种非常典型的 Bad Smell。
虽然大模型在训练的过程中,已经读过了很多优秀的代码,但是明确地给出存在坏味道的代码以及正确的写法,有助于大模型输出稳定、高质量的重构代码。
下面我们对这 10 种 Bad Smell 进行解读,这不仅有助于更深刻地理解这个技能能做什么,还有助于加深对代码重构的认知。
1. Long Method
坏味道:过长函数
举例:一个函数塞了两百行代码,从数据库查到数据清洗到业务计算到发通知全在里面。
深层问题:函数只有一个名字,但这个名字底下挂了六个各自独立的子任务,调试的时候想单独测试“更新库存”这个逻辑?无法做到,因为它是嵌套在两百行里面的。
重构思路:识别每个子任务各自的稳定边界是什么 —— 什么输入,什么输出,什么职责。把这些边界变成函数签名,内部的实现细节就变成了可以独立理解、独立测试的单元。
拆分过长函数的关键不是最终行数,行数只是结果。关键是你能不能用一句话描述这个函数在做什么——如果一句话里出现了“和”、“并且”、“还有”,说明该拆了。
2. Duplicated Code
坏味道:重复代码
举例:同样的 if-else 逻辑出现在三个地方,或者计算折扣的公式复制粘贴了两份。
深层问题:重复代码在初期往往是“先用后改”心态下的产物,当业务规则改变的时候——比如“银卡会员折扣从 10% 改成 12%”——需要在所有出现这段逻辑的地方逐一修改,漏掉一处就产生 bug。
重构思路:先问一个本质问题——这两个地方所做的事情是同一件事的本质,还是只是表面相似?如果是同一件事,把共同的逻辑提取出来,放到一个明确的位置,用参数处理差异点。Extract Method 是最常见的手段;如果重复跨越了类边界,可能需要 Extract Class 甚至建立共享的 Domain Service。重复代码的处理优先级通常较高,因为每多一处重复,就多一分未来修改时的遗漏风险。
3. Large Class/Module
坏味道:过大类/模块
举例:一个类有五十个方法,或者一个模块塞了二十个文件。
深层问题:类太大通常意味着它承担了多种不同变化的原因 —— 可能同时处理用户数据、发送邮件、生成报表、计算支付。这些变化原因彼此独立,但被绑在了一起。每一次业务变化都可能波及这个类,而每次波及都可能引入意外的副作用。SRP(单一职责原则)说的就是这个:一个类应该只有一个变化的原因。
重构思路:先对这个类做业务层面的 X 光检查 —— 它的方法能不能分成几组,每组服务不同的“使用者”?邮件相关的方法是不是其实属于一个 EmailService?报表相关的是不是属于 ReportService?识别出这些天然边界之后,用 Extract Class 把行为搬过去。这个过程往往还会暴露模块之间的隐含依赖,有助于重新划定边界。
4. Long Parameter List
坏味道:过长参数列表
举例:函数签名里有七八个参数,调用函数时容易搞错参数顺序。
深层问题:过长的参数列表往往意味着两件事:要么这个函数承担了不该承担的编排职责(它应该在更高层被调用,而不是自己凑齐全部依赖);要么这些参数本身有隐含的结构,只是没有被显式表达出来。调用方也痛苦—— 每次调用都要凑齐所有参数,漏掉一个就出错。
重构思路:先看这些参数能不能按概念分组 —— 地址相关的(街道、城市、国家)是不是可以封装成一个 Address 对象?用户信息和订单信息是不是本来就属于两个不同的概念?如果分组之后发现某些参数只是为了让函数构造自己的内部状态,可以考虑引入 Parameter Object 把它们打包,或者直接引入 Builder 模式让调用方逐步提供数据。
5. Feature Envy
坏味道:特性依恋
举例:一个类的方法大量访问另一个类的内部数据,比如说 Order 类里的 calculateDiscount 方法访问了 User 对象的七八个字段。
深层问题:数据和操作分离了。Discount 的逻辑依赖 User 的数据,但它不属于 Order —— 它在 Order 里,意味着每次读这段逻辑都要去 Order 的上下文里找。但如果这段逻辑的核心关注点是 User 的数据,为什么它不在 User 那边?
重构思路:问一个关键问题 —— 这段逻辑关心的是谁的数据?如果大部分字段来自另一个对象,说明逻辑应该移动到那个对象里面去。让数据和对数据的操作待在同一个地方,减少跨对象边界的取值逻辑。Move Method 就是这个用途。调整之后,调用方只需要“问”而不是“自己组装”——order.calculateDiscount(user) 比 Order 类自己去拿 user.membershipLevel、user.accountAge 然后自己算要清晰得多。
6. Primitive Obsession
坏味道:原始类型偏执
举例:用 string 类型来表示邮箱地址、手机号、URL。
深层问题:代码里充满了“裸类型”,业务含义需要靠变量名和注释来猜测。sendEmail(to, subject, body) 这个函数的问题是:这些概念没有任何运行时验证 —— 一个无效的邮箱地址可以毫无阻碍地传入函数,编译器无法检测出来。
重构思路:把有明确业务概念的变量包装为类型。例如:Email 类。它在构造对象时就验证格式。引入新类型不是过度设计——当一个概念在代码里反复出现、并且有“合法 vs 非法”的边界时,它就值得一个类型。
7. Magic Numbers/Strings
坏味道:魔法数字/字符串
举例:if (user.status === 2)、setTimeout(callback, 86400000)、discount = total * 0.15。
深层问题:数字和字符串字面量在代码里出现,但没有解释。86400000 是什么?你可能知道它是毫秒,但其他人需要花时间理解确认。魔法字符串(type === 'admin')同样危险 —— 拼错一个字就引入了一个难以追踪的 bug,而且没有任何编译器帮助。
重构思路:给每一个魔法值一个名字。const ONE_DAY_MS = 24 * 60 * 60 * 1000 不只是让代码好看,它把计算逻辑显式化了 —— 别人看到这个常量立刻知道这是“一天对应的毫秒数”,不需要逆向解读。枚举类型的引入(UserStatus.INACTIVE)让比较操作变得可搜索、可重构,编译器能帮上忙。
8. Nested Conditionals
坏味道:嵌套条件
举例:六层嵌套的 if 语句,每层都在缩小代码的可见范围,读代码需要从内到外反向理解。
深层问题:嵌套条件是一种“满足所有条件才执行”的思维模式 —— 这种模式在写代码的时候是顺着逻辑走的,但其他人在读代码的时候是从外到内逆向理解的。“如果用户没登录返回错误,如果用户没验证返回错误,如果订单无效返回错误,否则处理订单” —— 这种写法在脑子里需要同时维护所有条件的状态。层数越多,认知负荷越高,漏掉一个分支条件的概率也越大。
重构思路:反转会大幅改善可读性 —— 用 Guard Clause(卫语句)把“不满足条件就返回”提前,每个分支独立、线性、容易验证。if (!order) return { error: 'No order' } —— 这个函数在什么条件下不工作?更进一步可以用 Result/Either 类型把错误当作返回值而非异常,让成功路径始终是代码的主线。
9. Dead Code
坏味道:死代码
表象:注释掉的旧函数、未使用的 import。
深层问题:死代码有两个危害:第一,读者看到一段代码,不知道它是“有意保留还是忘了删”,会花时间去确认,浪费精力;第二,它会增加代码库的信噪比,掩盖真正重要的业务逻辑。
重构思路:发现即删除。删完之后跑测试,测试通过了说明这段代码确实没人用。如果未来需要这段逻辑,从 Git 历史中恢复。代码库里存活的代码越少,系统的可维护性越高。
10. Inappropriate Intimacy
坏味道:不当亲密
举例:order.user.profile.address.street 这种深度链式调用,一个类穿透多层封装去拿另一个对象的内部数据。
深层问题:这违反了迪米特法则(Law of Demeter) —— 对象只应该和直接邻居通信,不应该“跨三层”去拿邻居的邻居的数据。后果是牵一发动全身:如果哪天 Address 结构变了,所有写过 .user.profile.address.street 的地方都要改;某天 User 删掉了 Profile 字段,所有依赖这条链的代码都要跟着动。这种深度耦合在大型系统里是慢性的、扩散式的腐蚀。
重构思路:让每个对象自己管自己的数据,需要什么就问它。调用方应向 Order 索取街道信息,而不是自己去翻 Order 的内部结构。—— order.getShippingAddress()
除了 Code Smell,SKILL.md 里还有设计模式的引入示例,以及 18 种重构操作简介速查表。
通读 refactor 这个技能的 SKILL.md 文档,可以看到这是一份非常清晰且全面的局部代码重构指引。
但这个技能也有其不适用场景:如果你的重构范围跨越了多个文件,由于这个技能没有告诉大模型先调研代码的外部依赖关系,直接进行重构可能会出现问题。
最好搭配另外一个技能:test-driven-development 使用,才会达到最佳效果。
refactor-plan
npx skills add https://github.com/github/awesome-copilot --skill refactor-plan这个 Skill 的出发点完全不同:先调研,再规划,最后才动手。规划阶段明令禁止编辑任何文件。
这个 SKILL.md 文档的内容并不复杂,甚至可以说是很简洁的。值得我们学习的是这个技能文档中如何指引大模型进行重构计划制订的部分。
六条核心规划原则
原则一:规划阶段只读不写
Do not edit files while preparing the plan.
第一条规则是:在制订重构计划的过程中,不允许编辑任何文件。这有效避免了某些模型未等用户确认或提供足够测试,就开始自动改代码的行为。
原则二:充分阅读项目上下文
Search the codebase to understand the current state. Read enough implementation, tests, configuration, and docs to make the plan specific to the repository.
第二条规则让模型自行阅读项目的代码、测试、配置文件和文档,然后才制订计划。
这条指令的好处在于,如果代码不是用户写的,而是中途接手甚至全部由 AI 生成的,那么让模型拥有足够的上下文知识,会非常有助于提高后续重构的成功率。但如果只是想重构一小段代码,那么这条指令显然会浪费不少的 token。
原则三:识别影响范围与隐藏耦合
Identify affected files, ownership boundaries, dependencies, and likely hidden coupling.
第三条规则是这个技能中最重要特征的体现:让模型梳理出本次重构会涉及的文件、职责边界、依赖和隐藏的耦合。只有识别出这些关键因素,回归测试需要覆盖的范围才有明确的依据,从而显著降低重构带来的意想不到的风险。
原则四:自底向上的安全顺序
Plan changes in a safe sequence. Prefer contracts and types first, then implementations, then callers, then tests, then cleanup.
第四条规则告诉模型,即便识别出了依赖和耦合关系,在改动代码时,还是要遵循「自底向上」的原则。
原则五:分阶段验证 + 高风险步骤可回滚
Include verification steps between phases and a final validation command. Include rollback or recovery steps for the riskiest phases.
第五条规则告诉模型,在制订的计划中,需要为每步之间设置小验证,并为高风险步骤设置回滚机制。这一点非常有用,因为重构不当导致旧版本代码无法回滚、新版本代码又不能正常工作的情况,是我们最不愿看到的场景。
原则六:得到用户确认后再实施
Stop after the plan and ask for confirmation before implementing.
这个技能并不会在生成重构计划后就自作主张地开始重构,而是依然把人放在第一位,需要明确得到用户的确认后,才会进行真正的重构。
refactor-plan 的输出是一个 Markdown 格式的文档,文档的结构充分反映了这个技能的思想精华:
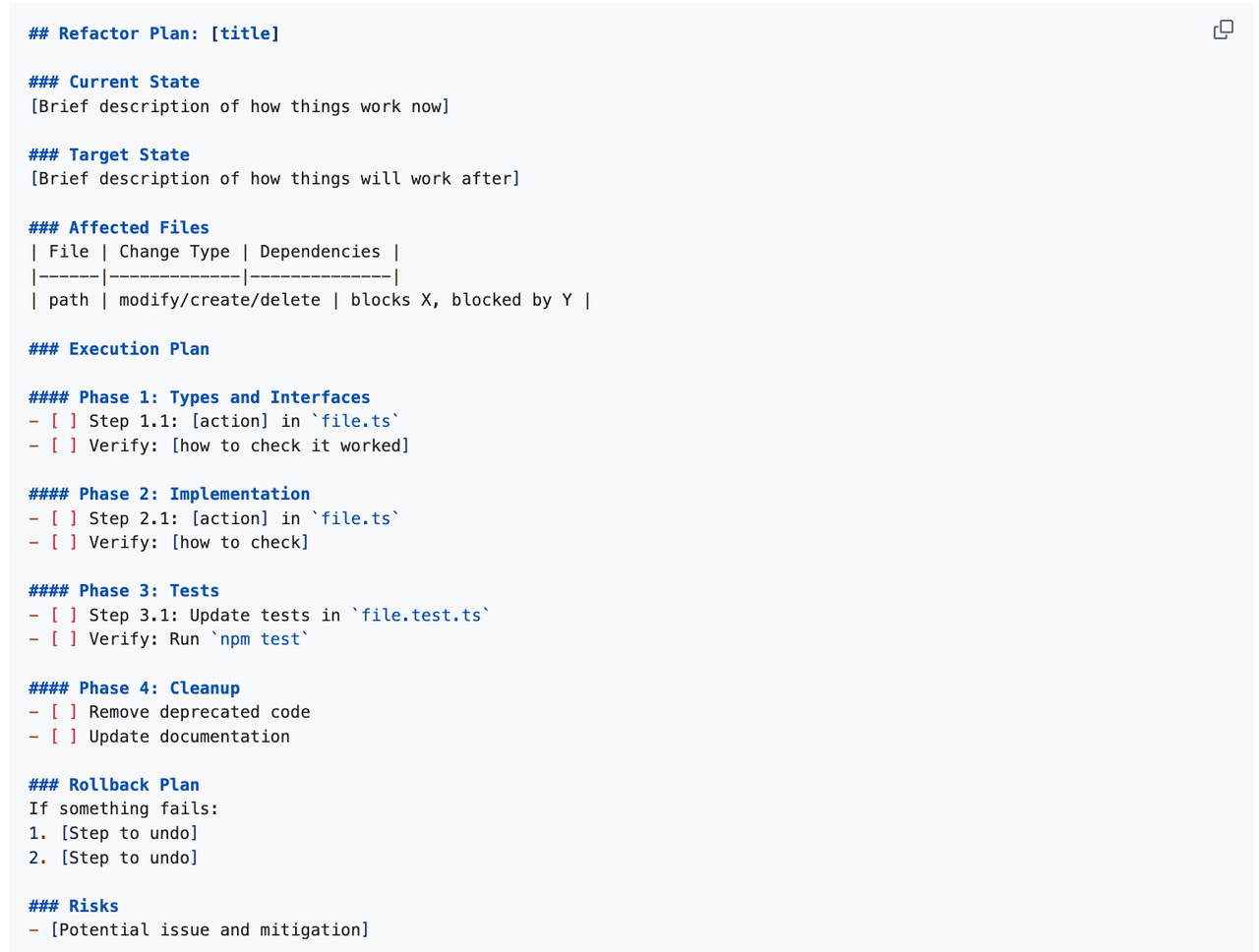
适用场景:多文件跨模块重构;接口/契约有变更的重构;AI Agent 执行重构任务的前置规划阶段。
不适用:单文件小范围重构(流程太重);紧急 hotfix。
结论:快速选型表
| 场景 | 推荐 |
|---|---|
| 单文件/单函数,有测试 | refactor |
| 多文件跨模块重构 | refactor-plan |
| 遗留代码,无测试覆盖 | 先写测试,再 refactor |
| 紧急 hotfix | refactor 直接动手 |
| AI Agent 执行重构 | refactor-plan(分阶段确认) |
组合这两个技能使用,效果最佳:先用 refactor-plan 输出施工图 → refactor 执行各阶段原子修改。